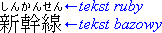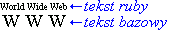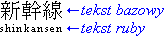Polskie tłumaczenie specyfikacji Ruby
Autor przekładu: Michał Górny
Lokalizacja dokumentu: http://podziemie.net/w3c/ruby/ruby
Dokument ten jest tłumaczeniem rekomendacji W3C Ruby Annotation. Przekład jest nienormatywny i może zawierać błędy powstałe podczas tłumaczenia. Status normatywny posiada jedynie wersja w języku angielskim dostępna pod adresem http://www.w3.org/TR/2001/REC-ruby-20010531.
W tłumaczeniu uwzględnione zostały następujące poprawki redakcyjne:
- E1 z 26 czerwca 2001
- E2 z 23 września 2003.
Ten dokument jest chroniony prawem autorskim. Copyright © 1998 – 2001 W3C® (MIT, INRIA, Keio). Wszelkie prawa zastrzeżone. Prawa autorskie zależne: Copyright © Michał Górny, 2004 – 2005.
„Ruby” to krótkie sekwencje tekstu położone wzdłuż tekstu bazowego, zazwyczaj używane w dokumentach wschodnioazjatyckich w celu zaznaczenia wymowy lub dostarczenia krótkiej adnotacji. Specyfikacja ta definiuje oznakowanie dla ruby w formie modułu XHTML [XHTMLMOD].
Ten rozdział opisuje status tego dokumentu w momencie jego publikacji. Inne dokumenty mogą zastąpić ten dokument. Aktualny status dokumentów z tej serii jest dostępny na stronach W3C.
Ten dokument został zaopiniowany przez Członków W3C i inne zainteresowane strony oraz został zatwierdzony przez Dyrektora jako Rekomendacja W3C. Jest to stabilny dokument i może być używany jako materiał odwoławczy lub cytowany jako odnośnik normatywny przez inny dokument. Rolą W3C w tworzeniu tej Rekomendacji jest przyciągnięcie do specyfikacji uwagi osób trzecich i wypromowanie jej w powszechnym użyciu. Rozszerzy to funkcjonalność Internetu i zwiększy możliwości wzajemnego współdziałania w jego ramach.
Ten dokument został stworzony przez Internationalization Working Group (I18N WG, Grupa Robocza do spraw Internacjonalizacji, tylko dla członków) przy pomocy Internationalization Interest Group (I18N IG) jako część działalności W3C Internationalization Activity. Komentarze powinny być nadsyłane na publicznie archiwizowaną listę dyskusyjną www-i18n-comments@w3.org. Mile widziane są również komentarze w językach innych niż angielski, w szczególności w języku japońskim. Publiczna debata na temat tego dokumentu odbywa się na liście dyskusyjnej www-international@w3.org (zobacz archiwum).
Ze względu na charakter poruszanych tematów, a także w celu uczynienia przykładów bardziej realistycznymi, dokument ten korzysta z szerokiego zakresu znaków. Nie każdy program użytkownika potrafi wyświetlać wszystkie te znaki. Sytuację może poprawić, w zależności od programu użytkownika, zmiana konfiguracji. Dołożono też wiele starań, by dokument ten był dostępny w różnych kodowaniach znaków obejmujących szeroki zakres programów użytkownika i konfiguracji.
Informacje związane z tym dokumentem można znaleźć na publicznej stronie dotyczącej ruby (http://www.w3.org/International/O-HTML-ruby). Znajdują się tam m.in. tłumaczenia tej specyfikacji, jak również ewentualne poprawki. Listę aktualnych Rekomendacji W3C oraz innych dokumentów technicznych można znaleźć pod adresem http://www.w3.org/TR.
Grupie Roboczej do spraw Internacjonalizacji nie przekazano żadnych deklaracji dotyczących patentów odnoszących się do tej specyfikacji.
Ten rozdział ma charakter informacyjny.
Niniejszy dokument prezentuje przegląd notacji ruby i definiuje dla niej oznakowanie. Przytoczono również kilka przykładów. Jednakże dokument ten nie określa żadnych mechanizmów prezentacyjnych czy stylizujących dla notacji ruby; zajmują się tym odpowiednie języki arkuszy stylów.
Dokument ten jest zorganizowany następująco:
Rozdział 1.1 stanowi przegląd notacji ruby.
Rozdział 1.2 stanowi przegląd oznakowania dla notacji ruby.
Rozdział 2 zawiera normatywną definicję oznakowania ruby.
Rozdział 3 omawia typowe sposoby renderowania i stylizowania tekstu ruby.
Rozdział 4 zawiera kryteria zgodności ze standardem.
Ruby to termin określający fragment tekstu skojarzony z innym fragmentem tekstu, określanym mianem tekstu bazowego. Tekst ruby jest używany w celu dostarczenia krótkiej adnotacji do skojarzonego tekstu bazowego. Najczęściej określa się w ten sposób czytanie (wskazówki dotyczące wymowy). Notacja ruby jest używana najczęściej w wielu rodzajach publikacji w Japonii, m.in. w książkach i magazynach. Ruby używa się też w Chinach, zwłaszcza w podręcznikach szkolnych.
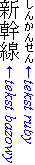
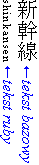
Tekst ruby jest zazwyczaj prezentowany wzdłuż tekstu bazowego, przy użyciu mniejszej czcionki. Nazwa „ruby” pochodzi od nazwy od nazwy czcionki wielkości 5,5 pt używanej w brytyjskim drukarstwie, która jest o około połowę mniejsza od czcionki wielkości 10 pt używanej zazwyczaj do normalnego tekstu. Rycina 1.1 przedstawia przykład z trzema ideogramami (kanji) jako tekst bazowy i sześcioma znakami hiragana określającymi czytanie (shinkansen — japoński szybki pociąg).
We wschodnioazjatyckiej typografii wykształciło się wiele cech niewystępujących w typografii zachodniej. Wiele z nich można osiągnąć bezpośrednio za pomocą języków arkuszy stylów, takich jak CSS czy XSL. Jednak do zdefiniowania związków pomiędzy tekstem bazowym a tekstem ruby potrzebne jest dodatkowe oznakowanie.
Niniejsza specyfikacja definiuje takie oznakowanie zaprojektowane do używania z XHTML, dzięki czemu tekst ruby jest dostępny w Sieci bez stosowania specjalnych zabiegów czy grafiki. Choć w specyfikacji tej, w celu ułatwienia zrozumienia oznakowania, podane są przykłady rzeczywistego renderowania, wszystkie one mają jedynie charakter informacyjny. Dokument ten nie określa żadnych mechanizmów prezentacji czy stylizowania; jest to pozostawione odpowiednim językom arkuszy stylów.
Bywa, że z tym samym tekstem bazowym jest skojarzony więcej niż jeden tekst ruby. Typowym przykładem jest wskazanie zarówno znaczenia, jak i czytania dla tego samego tekstu bazowego. W takich wypadkach teksty ruby mogą pojawić się po obu stronach tekstu bazowego. Często tekst ruby przed tekstem bazowym wskazuje czytanie, a po tekście bazowym — znaczenie. Rycina 1.2 przedstawia przykład tekstu bazowego z dwoma tekstami ruby wskazującymi czytanie przy pomocy znaków hiragana i liter alfabetu łacińskiego.
Poza tym każdy z tekstów ruby może być skojarzony z różnymi, lecz zachodzącymi na siebie fragmentami tekstu bazowego, tak jak w następującym przykładzie:
W tym przykładzie tekst bazowy to data „31 10 2002”. Jeden z tekstów ruby to „Data upływu ważności”. Ten tekst ruby jest skojarzony z całością tekstu bazowego. Drugi tekst ruby składa się z 3 części: „Dzień”, „Miesiąc” i „Rok”. Każda część skojarzona jest z innym fragmentem tekstu bazowego. „Dzień” jest skojarzony z „31”, „Miesiąc” jest skojarzony z „10”, a „Rok” jest skojarzony z „2002”.
Oznakowanie zdefiniowane w tej specyfikacji zaprojektowano tak, by obejmowało wszystkie powyższe przypadki, to znaczy oznakowanie dla jednego lub dwóch tekstów ruby skojarzonych z tym samym tekstem bazowym oraz oznakowanie służące do skojarzenia fragmentów tekstu (tekstów) ruby z częściami tekstu bazowego.
Są dwa rodzaje oznakowania ruby: proste oznakowanie ruby oraz złożone oznakowanie ruby. Proste oznakowanie ruby dokonuje skojarzenia pojedynczego tekstu ruby z sekwencją tekstu bazowego. W prostym oznakowaniu ruby można też zastosować mechanizm zabezpieczający, który umożliwia wyświetlenie tekstu ruby przez (starsze) przeglądarki nierozpoznające oznakowania ruby. Złożone oznakowanie ruby może skojarzyć dwa teksty ruby z jednym tekstem bazowym, za jego pomocą można też zdefiniować bardziej szczegółowe skojarzenia pomiędzy częściami tekstu ruby i tekstu bazowego. Złożone oznakowanie ruby nie umożliwia jednak zastosowania mechanizmu zabezpieczającego dla przeglądarek nierozpoznających oznakowania ruby.
Ten rozdział zawiera przegląd oznakowania ruby zdefiniowanego w tej specyfikacji. Pełna formalna definicja znajduje się w rozdziale 2.
Dla najprostszego przypadku oznakowanie ruby definiuje element ruby zawierający jeden element rb dla tekstu bazowego i jeden element rt dla tekstu ruby. Zatem element ruby tworzy skojarzenie pomiędzy tekstem bazowym a tekstem ruby — dla większości przypadków jest to wystarczające. Oto przykład prostego oznakowania ruby:
Może on być renderowany w następujący sposób:
Uwaga: Nazwa elementu otaczającego — „ruby” — powinna być interpretowana jako oznaczająca, że zawierające się w nim elementy kojarzą tekst ruby z tekstem bazowym. Nie można wyciągać z tej nazwy wniosku, że cała zawartość elementu, łącznie z tekstem bazowym, to jest ruby. Nazwę elementu otaczającego wybrano, by w sposób krótki i jasny oznaczyć funkcję całej struktury oznakowania; nazwy innych elementów wybrano, by zachować niewielką całkowitą długość.
Niektóre programy użytkownika mogą nie rozpoznawać oznakowania ruby lub nie potrafić renderować tekstu ruby we właściwy sposób. W każdym innym przypadku zasadniczo preferuje się renderowanie tekstu ruby, by nie stracić informacji. Powszechnie akceptowalnym zabezpieczeniem jest umieszczenie tekstu ruby bezpośrednio po tekście bazowym i objęcie tekstu ruby nawiasami. Nawiasy zmniejszają niebezpieczeństwo pomylenia tekstu ruby z innym tekstem. (Należy zaznaczyć, że tekst w nawiasach w japońskiej typografii nigdy nie jest nazywany „ruby”).
W celu zachowania kompatybilności ze starszymi programami użytkownika nierozpoznającymi oznakowania ruby i w zwykły sposób renderującymi zawartość nierozpoznawanych przez siebie elementów, do prostego oznakowania ruby można dodać elementy rp, by odróżnić tekst ruby.
Nazwa elementu rp oznacza „nawiasy ruby” (ruby parenthesis). Elementy rp i nawiasy (lub inne znaki) w nich zawarte służą jedynie za mechanizm zabezpieczający. Programy użytkownika ignorujące nieznane elementy, lecz renderujące ich zawartość, wyświetlą też zawartość każdego z elementów rp. Element rp może być zatem użyty do oznaczenia zarówno początku, jak i końca tekstu ruby.
Programy użytkownika obsługujące oznakowanie ruby rozpoznają element rp i świadomie nie wyświetlą jego zawartości. Zamiast tego będą renderować proste oznakowanie ruby w bardziej stosowny sposób.
Następujący przykład demonstruje użycie elementu rp:
Programy użytkownika, które:
- nie rozpoznają oznakowania ruby, lecz renderują zawartość nieznanych elementów, albo
- nie potrafią renderować tekstu ruby wzdłuż tekstu bazowego,
będą renderować powyższe oznakowanie jako:
Programy użytkownika, które rozpoznają oznakowanie ruby i oferują bardziej złożone style prezentacji tekstu ruby, nie będą jednocześnie renderować nawiasów. Na przykład oznakowanie z ryciny 1.6 może być renderowane w sposób pokazany na następnej rycinie.
Złożone oznakowanie ruby używane jest do kojarzenia więcej niż jednego tekstu ruby z tekstem bazowym lub do kojarzenia części tekstu ruby z częściami tekstu bazowego.
Złożone oznakowanie ruby obejmuje wielokrotne elementy rb i rt. Ta specyfikacja definiuje elementy-pojemniki zapewniające przejrzystość skojarzeń pomiędzy poszczególnymi elementami. Element-pojemnik dla tekstu bazowego dla ruby, rbc, obejmuje elementy rb. Może istnieć jeden lub dwa elementy-pojemniki dla tekstu ruby, rtc, obejmujące elementy rt. Pozwala to na skojarzenie dwu pojemników tekstu ruby z tym samym tekstem bazowym. Przy pomocy złożonego oznakowania ruby można również skojarzyć części tekstu bazowego z częściami tekstu ruby używając pewnej liczby elementów rb i odpowiadającej im liczby elementów rt. Dodatkowo elementowi rt może zostać przydany atrybut rbspan wskazujący, że pojedynczy element rt rozciąga się na wiele elementów rb (tzn. jest z nimi skojarzony). Przypomina to atrybut colspan dla elementów th i td w tabelach ([HTML4], rozdział 11.2.6).
Miejsce i sposób renderowania każdej z części złożonego oznakowania ruby jest definiowane przez odpowiednie języki arkuszy stylów. Więcej informacji na ten temat w rozdziale 3.
Poniższy przykład ukazuje wszystkie te cechy.
W tym przykładzie pierwszy pojemnik dla tekstu ruby obejmuje 3 składniki („Dzień”, „Miesiąc”, „Rok”). Każdy z tych składników skojarzony jest z odpowiednim składnikiem w tekście bazowym („31”, „10”, „2002”). Drugi z pojemników dla tekstu ruby („Data upływu ważności”) składa się z pojedynczego tekstu ruby i jest skojarzony z całością tekstu bazowego („31 10 2002”). Może być to renderowane w sposób pokazany na rycinie 1.10.
Przykład ten pokazuje, że w zależności od potrzeby można skojarzyć ze sobą mniejsze lub większe części tekstu ruby i tekstu bazowego. Na przykład tekst ruby może być skojarzony z całym tekstem bazowym, gdy:
- bardziej szczegółowe zależności są nieznane, lub
- gdy czytanie lub adnotacja odnoszą się tylko do całego tekstu bazowego i nie mogą być rozłożone na części.
Gdy znane są odpowiednie powiązania, można utworzyć bardziej szczegółowe skojarzenia. W tych przypadkach można też ulepszyć sposób renderowania. Na przykład zamiast traktować imię i nazwisko osoby jako całość, można utworzyć osobny tekst ruby dla imienia i osobny dla nazwiska; Złożone kanji lub cały zwrot mogą być rozłożone na części znaczeniowe lub pojedyncze znaki. W zależności od stopnia szczegółowości skojarzeń, zasięg tekstu ruby można dobrać odpowiednio do odstępów występujących w tekście bazowym, co pozwoli osiągnąć lepszą czytelność i bardziej zrównoważony układ wizualny.
W przypadku złożonego oznakowania ruby element rp jest niedostępny. Jest tak z dwóch powodów. Po pierwsze, element rp służy jedynie za mechanizm zabezpieczający; uważa się, że jest on dużo bardziej istotny dla częstszego przypadku oznakowania prostego. Po drugie, dla bardziej złożonych przypadków trudno wymyślić jakiś sensowny sposób wyświetlania elementów zabezpieczających, a stworzenie oznakowania dla takich przypadków byłoby jeszcze trudniejsze, jeśli nie niemożliwe.
Podsumowując, element ruby może zawierać jedną z następujących kombinacji:
- elementy
rb, rt i być może także rp (proste oznakowanie ruby), w celu:
- skojarzenia pojedynczego tekstu ruby z pojedynczym tekstem bazowym
- zabezpieczenia na wypadek braku obsługi oznakowania ruby.
- elementy-pojemniki: jeden
rbc i jeden lub dwa rtc (złożone oznakowanie ruby), w celu:
- skojarzenia dwóch tekstów ruby z tym samym tekstem bazowym
- zdefiniowania bardziej szczegółowych skojarzeń pomiędzy częściami tekstu ruby i częściami tekstu bazowego.
Ten rozdział ma charakter normatywny.
Ten rozdział zawiera formalną definicję składni i specyfikację funkcjonalności oznakowania ruby. Założono pewną znajomość ogólnych zasad modularyzacji XHTML, zwłaszcza specyfikacji Modularyzacja XHTML [XHTMLMOD].
Poniżej przedstawiono abstrakcyjną definicję elementów oznakowania ruby, która jest zgodna z ogólnymi zasadami modularyzacji XHTML [XHTMLMOD]. Dalsze definicje modułów abstrakcyjnych XHTML można znaleźć w [XHTMLMOD].
| Elementy |
Atrybuty |
Minimalny model zawartości |
| ruby |
Common |
(rb, (rt | (rp, rt, rp))) |
| rbc |
Common |
rb+ |
| rtc |
Common |
rt+ |
| rb |
Common |
(PCDATA | Inline - ruby)* |
| rt |
Common, rbspan (CDATA) |
(PCDATA | Inline - ruby)* |
| rp |
Common |
PCDATA* |
Maksymalny model zawartości dla elementu ruby jest następujący:
((rb, (rt | (rp, rt, rp))) | (rbc, rtc, rtc?))
Minimalny model zawartości dla elementu ruby jest identyczny z prostym oznakowaniem ruby. Alternatywa (rbc, rtc, rtc?) w maksymalnym modelu zawartości elementu ruby jest identyczna ze złożonym oznakowaniem ruby.
Implementacja tej abstrakcyjnej definicji jako moduł DTD XHTML znajduje się w dodatku A. Trwają prace nad implementacją w XML Schema [XMLSchema] (zobacz: [ModSchema]).
Element ruby jest elementem wewnątrzwierszowym (czyli umieszczanym na poziomie tekstu), służącym za ogólny pojemnik. Zawiera albo elementy rb, rt i opcjonalnie rp (proste oznakowanie ruby), albo elementy rbc i rtc (złożone oznakowanie ruby).
W przypadku prostego oznakowania ruby, element ruby zawiera albo element rb i następujący po nim element rt, albo sekwencję: element rb, element rp, element rt i drugi element rp. Zawartość elementu rt jest interpretowana jako tekst ruby i kojarzona z zawartością elementu rbrp, jeśli istnieje, jest ignorowana.
W przypadku złożonego oznakowania ruby, element ruby zawiera element rbc i, następujące po nim, jeden lub dwa elementy rtc. Zawartość podelementów każdego z elementów rtc jest interpretowana jako tekst ruby i kojarzona z zawartością podelementów elementu rbc jako tekstu bazowego.
Element ruby posiada tylko atrybuty wspólne. Przykłady atrybutów wspólnych to: id, class i xml:lang. Atrybuty wspólne zależą od języka znaczników z którym używane jest oznakowanie ruby. W przypadku [XHTML 1.1], są one zdefiniowane w specyfikacji Modularyzacja XHTML, rozdział 5.1 [XHTMLMOD].
Element rbc (ruby base container) służy za pojemnik na elementy rb w przypadku złożonego oznakowania ruby. Wewnątrz elementu ruby może się pojawić tylko jeden element rbc.
Element rbc posiada tylko atrybuty wspólne.
Element rtc (ruby text container) służy za pojemnik na elementy rt w przypadku złożonego oznakowania ruby. W celu skojarzenia tekstów ruby z pojedynczym tekstem bazowym (reprezentowanym przez element rbc), wewnątrz elementu ruby może się pojawić jeden lub dwa elementy rtc. Wewnątrz elementu ruby NIE MOGĄ się pojawić więcej niż dwa elementy rtc.
Element rtc posiada tylko atrybuty wspólne.
Element rb (ruby base) służy za oznakowanie dla tekstu bazowego. W prostym oznakowaniu ruby może się pojawić tylko jeden element rb. W złożonym oznakowaniu ruby wewnątrz elementu rbc może pojawić się wiele elementów rb. Każdy element rb jest skojarzony z odpowiednim elementem rt, dla zapewnienia szczegółowej kontroli prezentacji ruby.
Element rb może zawierać elementy wewnątrzwierszowe lub dane znakowe, ale jego elementem potomnym nie może być element ruby.
Element rb posiada tylko atrybuty wspólne.
Element rt (ruby text) służy za oznakowanie dla tekstu ruby. W prostym oznakowaniu ruby może się pojawić tylko jeden element rt. W złożonym oznakowaniu ruby wewnątrz elementu rtc może pojawić się wiele elementów rt, przy czym każdy z elementów rt zawiera tekst ruby dla powiązanego z nim tekstu bazowego reprezentowanego przez odpowiedni element rb.
Element rt może zawierać elementy wewnątrzwierszowe lub dane znakowe, ale jego elementem potomnym nie może być element ruby.
Element rt posiada atrybuty wspólne oraz atrybut rbspan. W złożonym oznakowaniu ruby atrybut rbspan zezwala elementowi rt rozciągać się na wiele elementów rb. Wartością atrybutu jest liczba całkowita większa od zera („0”). Wartością domyślną jest jeden („1”). Atrybut rbspan nie powinien być używany w prostym oznakowaniu ruby — jeśli się pojawia w takim oznakowaniu, programy użytkownika powinny go ignorować.
Element rp może być używany w przypadku prostego oznakowania ruby do ustalenia znaków określających początek i koniec tekstu ruby, gdy programy użytkownika nie posiadają innej możliwości przedstawienia tekstu ruby w sposób odróżniający go od tekstu bazowego. Nawiasy (lub podobne znaki) mogą służyć za akceptowalny środek zabezpieczający. W takiej sytuacji tekst ruby zostanie przeniesiony w dół i będzie renderowany wewnątrz linii, otoczony nawiasami zabezpieczającymi. Jest to najmniej niewłaściwe renderowanie w przypadku, gdy dostępne jest tylko renderowanie wewnątrzwierszowe. Element rp nie może być używany ze złożonym oznakowaniem ruby.
Element rp posiada tylko atrybuty wspólne.
Używanie nawiasów jako zabezpieczenia może prowadzić do trudności w odróżnieniu fragmentów tekstu mających być w zamierzeniu tekstem ruby, a innymi fragmentami tekstu zawartymi w nawiasach. Autor dokumentu lub arkuszu stylów powinien być świadomy możliwości wystąpienia takich trudności; zaleca się, by wybrał niewprowadzające dwuznaczności znaki zabezpieczające.
Ten rozdział ma charakter informacyjny.
W tym rozdziale omówione będą różne aspekty renderowania i stosowania stylów w kontekście oznakowania ruby zdefiniowanego w tym dokumencie. Dokument ten jednak nie określa żadnych mechanizmów prezentacji czy stylizowania; pozostawiono to odpowiednim językom arkuszy stylów. Właściwości formatujące dla stylizowania ruby są rozwijane w ramach CSS i XSL. Więcej szczegółów można znaleźć np. w specyfikacji „Moduł CSS3: Ruby” [CSS3-RUBY] (praca w toku).
Szczegóły formatowania ruby w kontekście japońskiego druku można znaleźć w JIS-X-4051 [JIS4051].
Termin „ruby” w języku japońskim używany jest tylko w odniesieniu do tekstu renderowanego wizualnie wzdłuż tekstu bazowego. Przypadki takie rozważane są w rozdziale 3.2 (rozmiar czcionki), rozdziale 3.3 (pozycjonowanie) i rozdziale 3.4 (prezentacja oznakowania ruby). Ten rodzaj prezentacji powinien być stosowany, gdzie to tylko możliwe. Wraz z wprowadzeniem ruby do WWW mogą się jednak pojawić pewne zjawiska i problemy niewystępujące w tradycyjnej typografii. Zdefiniowane w tej specyfikacji strukturalne oznakowanie dla ruby nie daje gwarancji, że tekst ruby będzie zawsze renderowany wzdłuż tekstu bazowego. Istniejące obecnie i mogące się pojawić w przyszłości urządzenia do renderowania dokumentów z oznakowaniem XHTML charakteryzują się dużą różnorodnością. Oto możliwe sytuacje, w których uzasadnione jest odmienne renderowanie:
- W niewizualnych programach użytkownika, takich jak przeglądarki głosowe i programy brajlowskie, możliwe jest tylko renderowanie sekwencyjne. Więcej na temat renderowania niewizualnego w rozdziale 3.5.
- Wyświetlanie tekstu ruby o takiej jak zwykle wielkości na ekranach o niskiej rozdzielczości może być niewykonalne. Można wtedy użyć zabezpieczeń. Więcej informacji w rozdziale 3.6.
- W niektórych wypadkach dla celów edukacyjnych może być interesujące ukrycie tekstu ruby z jednoczesnym udostępnieniem go jako pop-up. Jest to niemożliwe na papierze, lecz łatwo wykonalne na urządzeniu z wyświetlaniem dynamicznym.
W typowym zastosowaniu rozmiar czcionki tekstu ruby jest równy mniej więcej połowie tekstu bazowego. W istocie nazwa „ruby” pochodzi od nazwy czcionki wielkości 5,5 pt używanej w brytyjskim drukarstwie; jest ona około połowę mniejsza od 10-punktowej czcionki zazwyczaj używanej do normalnego tekstu.
Tekst ruby może być usytuowany względem tekstu bazowego na kilka sposobów. Ponieważ teksty wschodnioazjatyckie mogą być renderowane zarówno pionowo, jak i poziomo, używane są tutaj terminy „przed” i „po” zamiast „powyżej” i „poniżej”, czy „na prawo” i „na lewo”. Wyrazy „przed” i „po” powinny być rozumiane jako „przed”/„po” linii zawierającej tekst bazowy. Odpowiedniość między tymi terminami jest ukazana w poniższej tabeli:
| Terminologia |
Układ poziomy
(od lewej do prawej, z góry na dół) |
Układ pionowy
(z góry na dół, od prawej do lewej) |
| przed |
powyżej |
na prawo |
| po |
poniżej |
na lewo |
Teksty ruby najczęściej umieszczane są przed tekstem bazowym (zobacz: rycina 1.1 i rycina 3.2).
Czasami, zwłaszcza w dokumentach edukacyjnych o układzie poziomym, tekst może się pojawiać po tekście bazowym, tj. poniżej (zobacz: rycina 3.1). W języku chińskim tekst ruby z transkrypcją pinyin zazwyczaj umieszczany jest po tekście bazowym. Tekst ruby może pojawiać się po tekście bazowym także w układzie pionowym (zobacz: rycina 3.3). We wszystkich tych przypadkach kierunek pisania tekstu ruby jest taki sam, jak tekstu bazowego — pionowy, jeśli tekst bazowy jest pionowy, poziomy, jeśli tekst bazowy jest poziomy.
W tradycyjnych chińskich tekstach tekst ruby w alfabecie bopomofo może pojawiać się wzdłuż prawej krawędzi tekstu bazowego nawet w układzie poziomym.
Zauważ, że oznaczenia tonów bopomofo (w powyższym przykładzie w kolorze czerwonym) zdają się znajdować w osobnej kolumnie (wzdłuż prawej krawędzi tekstu ruby w bopomofo), mogą być zatem postrzegane jako „ruby na ruby”. Są one jednak zakodowane jako część tekstu ruby. Szczegóły tego kodowania wykraczają poza zakres niniejszego dokumentu.
Ta specyfikacja nie przesądza o sposobie wyświetlania oznakowania ruby. Do określenia dokładnego zachowania oznakowania ruby na ogół będą używane arkusze stylów.
Uwaga. Chociaż renderowanie tekstów ruby powinno być kontrolowane przez arkusze stylów, w wypadku niedostarczenia informacji o stylach przez autora i użytkownika zalecane jest, by wizualne programy użytkownika umieszczały tekst ruby przed tekstem bazowym, gdy jest tylko jeden tekst ruby. Dotyczy to też prostego oznakowania ruby. Gdy są dwa teksty ruby, pierwszy z nich powinien być umieszczony przed tekstem bazowym, a drugi — po tekście bazowym. Przykładowy domyślny arkusz stylów dla programów użytkownika opisujący to formatowanie będzie zawarty w [CSS3-RUBY] i dokumentach go zastępujących.
W przypadku renderowania niewizualnego pod nieobecność informacji o stylach, zalecane jest renderowanie zarówno tekstu bazowego, jak i tekstu/tekstów ruby, z zaznaczeniem (np. różna barwa czy wysokość głosu) statusu każdego z nich.
By umożliwić arkuszom zastosowanie stylów, a innym mechanizmom właściwe renderowanie tekstu ruby, ważne jest udostępnienie odpowiedniej ilości informacji o funkcji każdego ze składników. Następujący przykład ilustruje użycie atrybutu class w celu umożliwienia zdefiniowania przez arkusze stylów dokładnego sposobu prezentacji tekstu ruby. Klasa „czytanie” jest użyta dla tekstu ruby wskazującego czytanie. Klasa „adnotacja” jest użyta do wskazania tekstu ruby używanego do adnotacji. Atrybut xml:lang wskazuje na język tekstu.
Przy użyciu arkusza stylów, który określałby pionowy tekst, renderowanie czytania przed tekstem bazowym i renderowanie adnotacji za tekstem bazowym, powyższe oznakowanie mogłoby być renderowane w ten sposób:
Dokumenty zawierające oznakowanie ruby będą musiały w niektórych przypadkach być renderowane przez niewizualne programy użytkownika, takie, jak przeglądarki głosowe i brajlowskie programy użytkownika. Dla takich scenariuszy renderowania ważne jest zrozumienie, że:
- Właściwe mogą być różne sposoby renderowania, w zależności od użytkownika i od sytuacji.
- Tekst ruby oznaczający czytanie czasem będzie musiał być traktowany inaczej, niż tekst ruby zawierający inne informacje.
- Ważne dla właściwego renderowania niewizualnego jest wskazanie funkcji, jaką pełni każdy z tekstów ruby.
- Czasem występują różnice pomiędzy czytaniem wskazywanym przez tekst ruby a faktyczną wymową.
- Czytelnik może być zainteresowany zasięgnięciem informacji o (ideograficznym) tekście bazowym.
W zależności od potrzeb użytkownika, sposób czytania tekstu może być zróżnicowany: od bardzo szybkiego i pobieżnego do bardzo starannego i szczegółowego. Może to prowadzić różnego traktowania tekstu ruby w renderowaniu niewizualnym, od pomijania tekstu ruby w szybkim czytaniu do szczegółowej analizy struktury ruby i faktycznie użytych znaków w czytaniu starannym.
Gdy, jak się często zdarza, tekst ruby reprezentuje czytanie, renderowanie zarówno tekstu bazowego, jak i tekstu ruby może prowadzić do irytujących powtórzeń. Syntezator mowy może potrafić poprawnie wymawiać tekst bazowy na podstawie rozległego słownika, w innych przypadkach może potrafić wybrać prawidłową wymowę na podstawie czytania określonego przez tekst ruby.
Nie każdy tekst ruby przedstawia wymowę. Autorzy powinni rozróżniać teksty ruby używane do różnych celów przy pomocy atrybutu class. Zademonstrowano to powyżej, używając class="czytanie" dla tekstu ruby wskazującego czytanie.
Tekst ruby wskazujący czytanie może nie prowadzić do prawidłowej wymowy nawet wtedy, gdy użyte pismo na pierwszy rzut oka wygląda na idealnie fonetyczne. Na przykład bopomofo jest kojarzone niezależnie dla każdego znaku tekstu bazowego; nie są przy tym oddawane dźwięki zależne od kontekstu, czy zmiany tonu. Podobnie, w języku japońskim mogą wystąpić nieregularności ortograficzne, takie jak używanie „は” (ha w hiragana) jako przedrostka tematu wymawianego „わ” (wa), bądź używanie samogłosek do wskazywania przedłużenia. W takich przypadkach autorzy mogą chcieć opatrzyć właściwą wymowę stworzonym specjalnie do tego celu oznakowaniem, mogą też zdać się na system renderujący dźwięk potrafiący prawidłowo obsłużyć takie przypadki.
Jeśli autorowi nie zależy na zabezpieczeniach dla programów użytkownika nierozpoznających oznakowania ruby ani nieobsługujących arkuszy stylów CSS2 [CSS2] lub XSL [XSL], elementy rp są niepotrzebne.
Mimo to, możliwe jest zastosowanie zabezpieczenia w postaci objęcia tekstu ruby nawiasami, jeśli na przykład rozdzielczość urządzenia nie jest odpowiednia dla tradycyjnego renderowania ruby. W [CSS2] nawiasy mogą być generowane przy użyciu właściwości content ([CSS2], rozdział 12.2) wykorzystując pseudoelementy :before i :after ([CSS2], rozdział 12.1), tak jak w następującym fragmencie stylu:
W powyższym przykładzie nawiasy zostaną automatycznie dodane wokół elementu rt. Zakłada się, że powyższe reguły stylów używane są razem z regułami stylów umieszczającymi tekst ruby wewnątrz wiersza. Generacja nawiasów jest prosta również przy użyciu XSLT [XSLT].
Ten rozdział ma charakter normatywny.
W kontekście tej specyfikacji, zgodność ze standardem może dotyczyć: oznakowania, typów dokumentu, implementacji modułów, dokumentów, generatorów oraz interpreterów. W większości z tych przypadków dostępne są dwa poziomy zgodności: zgodność prosta i zgodność pełna. Zgodność prosta oznacza, że obiekt zgodny ze standardem obsługuje minimalny model zawartości elementu ruby z rozdziału 2.1, tj. tylko proste oznakowanie ruby. Zgodność pełna oznacza, że obiekt zgodny ze standardem obsługuje maksymalny model zawartości elementu ruby z rozdziału 2.1, tj. obsługiwane jest zarówno proste, jak i złożone oznakowanie ruby.
Oznakowanie jest prostym oznakowaniem ruby zgodnym ze standardem, jeśli zawiera jeden lub więcej elementów ruby i zawartość wszystkich tych elementów (włączając w to elementy bezpośrednio potomne) jest zgodna z minimalnym modelem zawartości z rozdziału 2.1 (tj. dozwolone jest tylko proste oznakowanie ruby). Oznakowanie jest złożonym oznakowaniem ruby zgodnym ze standardem, jeśli zawiera jeden lub więcej elementów ruby i zawartość wszystkich tych elementów (włączając w to elementy bezpośrednio potomne) jest zgodna z maksymalnym modelem zawartości z rozdziału 2.1 (tj. dozwolone jest zarówno proste, jak i złożone oznakowanie ruby).
Typ dokumentu jest typem dokumentu prostego oznakowania ruby zgodnym ze standardem, jeśli włącza zgodne ze standardem proste oznakowanie ruby poprzez dodanie elementu ruby do odpowiednich elementów (takich, jak elementy wewnątrzwierszowe) oraz poprzez zdefiniowanie niezbędnych elementów i atrybutów. Typ dokumentu jest typem dokumentu pełnego oznakowania ruby zgodnym ze standardem, jeśli włącza zgodne ze standardem pełne oznakowanie ruby poprzez dodanie elementu ruby do odpowiednich elementów (takich, jak elementy wewnątrzwierszowe) oraz poprzez zdefiniowanie niezbędnych elementów i atrybutów.
Implementacja modułu (np. przy pomocy technologii DTD lub XML Schema) jest implementacją modułu prostego ruby zgodną ze standardem, jeśli jest zaprojektowana tak, że łączy proste oznakowanie ruby z innymi modułami w opisane powyżej typy dokumentu. Implementacja modułu jest implementacją modułu złożonego ruby zgodną ze standardem, jeśli jest zaprojektowana tak, że łączy pełne oznakowanie ruby z innymi modułami w opisane powyżej typy dokumentu. Implementacja modułu jest implementacją modułu pełnego ruby zgodną ze standardem, jeśli jest zaprojektowana tak, że łączy proste lub pełne oznakowanie ruby z innymi modułami w opisane powyżej typy dokumentu (np. poprzez udostępnienie przełącznika lub dostarczenie dwu osobnych implementacji modułu).
Dokument jest dokumentem prostego oznakowania ruby zgodnym ze standardem, jeśli zawiera zgodne ze standardem proste oznakowanie ruby, ale nie zawiera złożonego oznakowania ruby, ani oznakowania ruby niezgodnego ze standardem. Dokument jest dokumentem pełnego oznakowania ruby zgodnym ze standardem, jeśli zawiera zgodne ze standardem pełne oznakowanie ruby, ale nie zawiera oznakowania ruby niezgodnego ze standardem.
Generator jest generatorem prostego oznakowania ruby zgodnym ze standardem, jeśli generuje zgodne ze standardem proste oznakowanie ruby, ale nie generuje złożonego oznakowania ruby, ani oznakowania ruby niezgodnego ze standardem. Generator jest generatorem pełnego oznakowania ruby zgodnym ze standardem, jeśli generuje zgodne ze standardem pełne oznakowanie ruby, ale nie generuje oznakowania ruby niezgodnego ze standardem.
Interpreter jest interpreterem prostego oznakowania ruby zgodnym ze standardem, jeśli odrzuca proste oznakowanie ruby niezgodne ze standardem, przyjmuje proste oznakowanie ruby zgodne ze standardem oraz, gdy interpretuje oznakowanie ruby, robi to zgodnie z tą specyfikacją. Interpreter jest interpreterem pełnego oznakowania ruby zgodnym ze standardem, jeśli odrzuca oznakowanie ruby niezgodne ze standardem, przyjmuje pełne oznakowanie ruby zgodne ze standardem oraz, gdy interpretuje oznakowanie ruby, robi to zgodnie z tą specyfikacją. Przykładami interpreterów są narzędzia do analizy lub transformacji po stronie serwera oraz programy renderujące.
Informacje o zgodności ze standardem Modularyzacji XHTML znajdują się w rozdziale 3 [XHTMLMOD].
Ten rozdział ma charakter informacyjny.
W opracowywaniu poprzednich projektów jako redaktorzy brali udział Takao Suzuki (鈴木 孝雄) i Chris Wilson.
Powstanie tej specyfikacji nie byłoby możliwe bez pomocy, której udzielili członkowie I18N WG W3C, w szczególności Mark Davis i Hideki Hiura (樋浦 秀樹), a także członkowie I18N IG W3C.
Inni współpracownicy: Murray Altheim, Laurie Anna Edlund, Arye Gittelma, Koji Ishii, Rick Jelliffe, Eric LeVine, Chris Lilley, Charles McCathieNevile, Shigeki Moro (師 茂樹), Chris Pratley, Nobuo Saito (斎藤 信男), Rahul Sonnad, Chris Thrasher.
Oznakowanie zdefiniowane w tej specyfikacji zostało uzgodnione z oznakowaniem ruby w [JIS4052], opracowanym przez Grupę Roboczą nr 2 (WG 2 – Skład tekstu) Komitetu Dochodzeniowo-Badawczego ds. Standaryzacji Systemów Elektronicznego Przetwarzania Dokumentów będącego częścią Japońskiego Towarzystwa Standaryzacyjnego. Chcielibyśmy również podziękować członkom WG 2, zwłaszcza Kohji Shibano (芝野 耕司, przewodniczący) i Masafumi Yabe (家辺 勝文, współpracownik) za współpracę z ich strony. Pod względem technicznym oznakowanie dla ruby w [JIS4052] różni się od oznakowania w tej specyfikacji w dwóch punktach. Po pierwsze, istnieje tam alternatywna forma oznakowania niezgodna z XML, oparta na specjalnych symbolach, a po drugie, element rp jest niedozwolony.
Wartościowe komentarze podczas ostatniej procedury przeglądowej otrzymano też od: Grup Roboczych ds. HTML, CSS, XSL, WAI P&F, od Stevena Pembertona, Trevora Hilla, Susan Lesch i Franka Yung-Fong Tanga. Akira Uchida (内田 明) udzielił komentarzy z punktu widzenia tłumacza.
Wcześniejsza propozycja oznakowania ruby, wykorzystująca atrybuty, jest opisana w [DUR97].